GAN的综述(2020.3)
以下内容由我的CSDN博客迁移。
上一节我们学习了 GAN 的基本概念, 这一节我们将过去几年的 GAN 经典算法思想都介绍一下。
一、GAN的数学解释
上一节我们学习了 GAN 的基本算法,现在让我们看看 GAN 背后的数学思想。
- 生成器
生成器实际上产生了一个生成数据分布\(P_G(x)\)。它的目标就是使得\(P_G(x)\)与\(P_{data}(x)\)之间的差距尽可能小。

- 判别器
判别器可以产生一个分值,用来描述生成分布与真实分布之间的差异,此时这个分值由目标函数定义,例如最原始的 GAN 使用二类交叉熵损失来描述。我们的目标就是最大化这一差异。
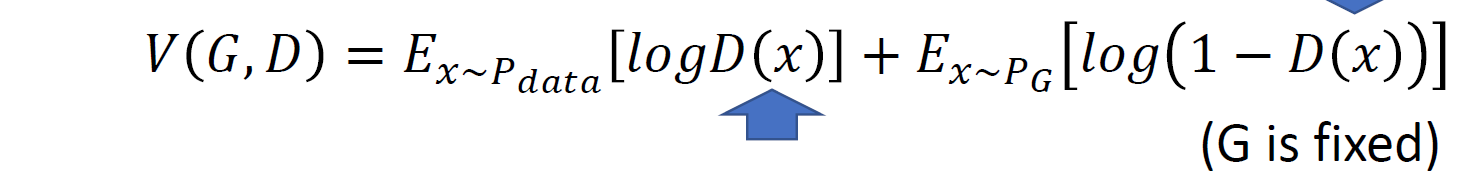
事实上,这里的目标函数相当于衡量两个分布之间的JS散度。我们之前提到过有KL散度,也说了KL散度的不对称性,而JS散度就是两个相对的KL散度的平均。 数学证明如下: 首先我们解出判别器在生成器固定时的最大值。


之后代入\(\max_DV(G, D)\), 可以看到:
 得证。
得证。
由于我们最终目的是要使得生成分布与真实分布尽可能小,因此我们最终的优化问题为 \[G^*=\argmin_G\max_DV(G, D)\]
这里判别器与目标函数充当了描述差异的函数,因此我们不能在每次循环时过多的更新生成器,而可以多更新几次判别器。 这是因为如果更新生成器过多,它的生成分布就与更新前的生成分布差异很大,这使得判别器产生的数值并不能很好描述差异性。对于 GAN 的一个重要假设就是生成器的每次小更新产生的新分布与之前的分布差异不太多,从而使得描述的差异仍有效。
二、 fGAN
上节阐述了原始的 GAN 衡量的是 JS 散度,那么有没有其他的衡量差异的选择呢?另外为什么判别器可以表示某一散度的度量呢?本节将回答这一问题。
在概率统计中,f散度是一个函数,这个函数用来衡量两个概率密度p和q的区别。
p和q是同一个空间中的两个概率密度函数,它们之间的f散度可以用如下方程表示:
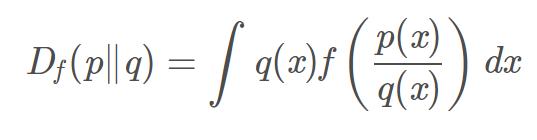
其中\(f\)为凸函数且\(f(1) = 0\) 因此当两个分布相同时,它们的 f 散度就是 0 。并且由于凸函数的性质,f 散度保证它的最小值就是0。 我们不难发现一些常见的散度都可以被表示:

这里给出了一些常见的散度与其相应的 f 函数:

那么生成器与损失函数为什么能够表示某一散度呢?
这里我们引入共轭的概念,每个凸函数\(f\)都有一个共轭函数\(f^*\)。定义为:

同样,共轭函数的共轭就是原函数,即 \(f(x)=\max_{t\in dom(f^*)}\{xt-f^*(t)\}\)
- 例如,对于\(f(x)=x\log x\),
我们求它的共轭函数 \[f^*(t)=\max_{x\in dom(f)}\{xt-x\log x\}\] 要求最大值就是对x求导得到\(x=\exp(t-1)\)代入便得到 \[f^*(t)=\exp(t-1)\]
现在回想 f 散度,我们将 x 视为 \(p(x)\over q(x)\) 得到
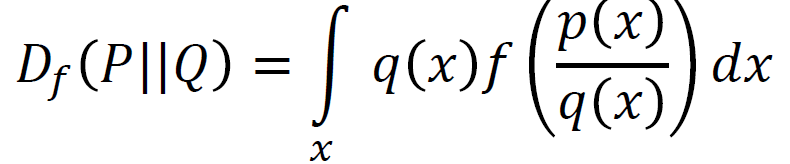

此时这个优化问题很难解出,这时我们便引入判别器\(D(x)\),让它来代替我们去寻找最优值,即\(D(x)\)的输入是 \(x\) 而输出是 \(t\) , 因此有:

由于\(D(x)\)的容量是有限的,因此它只能是 f 散度的一个下界,但是我们可以找到使得这个式子最大的\(D(x)\), 从而进行一个近似:

不难发现这和 GAN 的损失函数很相似,事实就是如此。因此我们最终优化函数其实就是

但是无论选择什么散度,我们都有可能遇到 mode collapse 的问题,如图,可能某一样本的概率密度十分大:

对于这个问题,我们将在后面解决。
三、Conditional GAN
最原始的 GAN 的输入只是随机产生的向量,并没有什么具体解释,我们只能认为是向量的每个值可能对应输出的许多特征。那么有什么方法可以让我们控制输出的条件呢?
如果我们已经有了一个标注好所有图片的特征的数据集,解决的方法就十分简单,我们只需要按照监督学习的思想,将标注也作为输入输入进生成器,然后用判别器进行打分,进行对抗训练即可。
但要注意的是,判别器这时不能只对图片生成的质量进行评分,还需要对生成图片与是否符合描述进行打分,也就是说判别器的输入也应该有描述,同时损失项一共有三个:真实图片与相符合的描述;真实图片与其不相符的描述以及假的图片。 如图:

判别器的架构一般如下:

要么是两个输入先独立进入网络然后整合在一起,要么是一个神经网络用来判别图像的真实性另一个神经网络判别是否符合描述。个人认为第二种可能效果会更好,因为它区分了真实性和符合度,而第一种将两个的评分糅合在了一起,使得有可能朝着不同于评分的方向优化。
四、infoGAN
在常规的 GAN 中,我们期望随机向量的每一个维度的数值变换对应一个特定的特征,但是事实往往并非如此:

为了让特征更加清晰,我们可以引入自编码器的思想:

如图,其中输入 z 由两部分组成:一部分是设计向量 c ,它包含着我们期望有意义的一些维度,例如头发颜色、大小等等…… z' 是随机生成的向量,代表着我们未知的维度。我们借助了自编码器的思想,我们加入了一个新的“解码器”,它可以对生成器产生的输出进行分类,输出一个向量 c ,每个维度的向量的意义与输入相同。因此生成器和分类器就共同构成了一个自编码器。由于都是处理生成器的输出,因此判别器和分类器可以在底层共享权重,减少计算量。这就是 InfoGAN 的思想。它强制向量 c 对生成的图片需要有很大的影响
借助自编码器的思想,我们还可以构造许多 GAN 的架构,例如 VAE-GAN, BiGAN 等等。 Bi-GAN:

五、无监督 GAN
很多时候我们不会遇到监督问题,更多的是 one-shot 问题,例如风格迁移等等,我们不能获取真实的标注,此时我们就需要进行无监督学习。此时主要有两种途径:
- 直接转换:

这种转换一般不会对原输入有太大的改变,适合较少的迁移。
- 映射特征:借助自编码器的思想,用 Endoder 提取输入的特征,然后用 Decoder 生成另一个分布的输出。

这种方法适用于输入和输出的分布差别很大的情况,只有相关特征被保留。
现在我们分别说一说两个途径的具体实现:
直接转换
直接借助 Conditional GAN 的思想,将 Domain X 当作给定的条件,进行训练:

然而生成器有可能生成一个与条件完全不相关但又可以骗过判别器的图片,针对这一问题,有几种解决方法:
- 直接无视: 如果我们的生成器网络比较简单,不难想象它的输出不会与输入条件差太多,因此这种方法还是有可行性的。
- 引入另一个预训练过的网络当作编码器,使得在生成器的输入和输出中提取的特征尽可能相似。这样就可以强制生成器的输入与输出相似。

- Cycle GAN
首先,我们建立一个自编码器与 GAN 结合的结构, 还原的图像必须和原图像差不多:

这使得输出必须保留输入的信息,否则没有办法还原。 然后,我们把 Encoder 和 Decoder 对调一下,引入一个新的 判别器,使得生成器同时学习到 domain Y 的特征。

以上构成了 CycleGAN
还有一些网络结构和 CycleGAN 相当,例如 Disco GAN, Dual GAN等等。

Star GAN
我们介绍了两个 domain 的情况,但如果有多种风格,使用上述方法可能十分复杂。 而 StarGAN 只是用一个生成器就解决了这个问题。它的具体训练过程如图:

判别器不仅需要识别真假,还需要对图像来自哪个 domain 进行分类;而生成器在生成指定 domain 的图像后,需要把生成的图像再输入回生成器让它还原到原来的 domain,构成了一个自编码器。
重映射
基本思想是我们训练两个独立的自编码器,然后想办法让两个编码器提取的特征代表相当,从而使得一个编码器的特征可以被另一个解码器构造图片。

主要有以下几个方法:
- 权重共享

将两个自编码器的一些层数的权重共享,以期望能提取相似的特征。
- 增加判别器:

增加一个 Domain Discriminator 来区分特征属于哪个 domain ,两个 encoder 需要另外骗过判别器,这样就可以使得两者提取的特征相当。
- 借助Cycle思想

将 ENx 的产出直接喂入 DEy ,然后再把生产的图像喂入 ENy , 产出喂入 DEx,这样一番产生的最终图像和原图需要尽量相似,如此实现了无监督学习的 domain transfer。
当然,也可以直接比较 ENy 和 ENx 的特征值的相似性。
六、WGAN
第二节我们介绍了尽管使用不同的散度,它们仍然不能够很好地反映生成分布和真实分布之间的差距。
- 自然生成的数据经常是一个在高维空间中嵌入的低维流形,因此不同的分布之间实际上的重叠部分是可以忽略的,这直接导致了散度无法进行测量。

如图,这是在二维空间中两个一维流形,我们不难发现两者间的重叠可以忽略。
- 另外,即便考虑两个分布间的重叠,我们也无法采样出足够多的数据来描述它们的差异。

如图, 由于没有足够的样本,我们学习到的很可能与实际大不相同。
以 JS 散度为例,尽管在特定情况下它可以很好地表示两个分布的差异,但是当两个分布完全不重叠时, 无论它们的距离有多远,JS散度永远是 \(\log 2\) 此时我们无法学习到更多的信息,因此散度有着很大的缺陷。
那么我们有什么方法来解决它呢?
这里我们引入 Wasserstein 距离,它又叫 Earth Mover's Distance, 基本想法如下,我们将两个分布看作两个土堆,我们需要用推土机将一个土堆的形状变成另一个的形状,这当然有许多的方案,我们去平均移动距离最小的方案作为 Wasserstein 距离。

即:

总而言之, 它的具体定义如下:
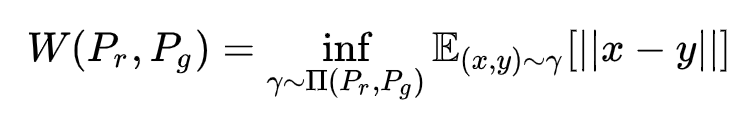
其中 \(\Pi\) 是两个分布组合起来的所有可能的联合分布的集合。对于每一个联合分布,可以进行采样得到真实样本 x 和生成样本 y , 并计算这对样本的距离。它们所有的平均距离就是期望值。在所有可能的分布中能够对这个期望取到的下界就是 Wassertein 距离。
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。
- 那么我们怎样去运用这一距离呢?
不难发现定义的距离需要求出一个下界,而这个问题没法直接求解,经过一些定理推导后,我们得到了下面这个式子:

之前我们介绍过 Lipchitz 连续,它就是对一个连续函数\(f\)上的额外限制,要求存在一个非负的常数 K 使得定义域内任意两个元素满足:
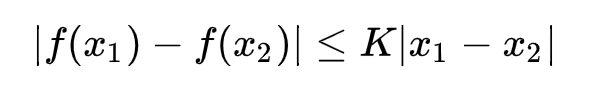
此时称\(f\)的 Lipschitz 常数为 K。 上面这个公式的意思就是在函数\(f\)的 Lipschitz 常数不超过 K 的条件下,去后面这个式子的上界,再除以 K 。此时我们就可以训练判别器 D(x) 代替\(f\),用深度学习去寻找上界。

这样我们需要考虑怎么使得 D 满足约束,原始的 WGAN 采用了简单的做法,就是限制 D 的所有参数的不超过某个范围\([-c, c]\), 此时一定存在某个常数 K 使得 D 的局部变动幅度不超过它。满足了约束。
因此 WGAN 虽然推导很复杂,但是它仅仅对原始的 GAN 进行了很少的改动:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
第四点是作者从实验中发现的,属于trick,相对比较“玄”。作者发现如果使用Adam,判别器的loss有时候会崩掉,当它崩掉时,Adam给出的更新方向与梯度方向夹角的cos值就变成负数,更新方向与梯度方向南辕北辙,这意味着判别器的loss梯度是不稳定的,所以不适合用Adam这类基于动量的优化算法。作者改用RMSProp之后,问题就解决了,因为RMSProp适合梯度不稳定的情况。
这便是它的完整流程:

七、WGAN++
上一节我们介绍了原始 WGAN 的算法,然而weight clipping的实现方式存在两个严重问题:
- weight clipping独立地限制每一个网络参数的取值范围,在这种情况下我们可以想象,最优的策略就是尽可能让所有参数走极端,要么取最大值(如0.01)要么取最小值(如-0.01)
这样带来的结果就是,判别器会非常倾向于学习一个简单的映射函数。判别器没能充分利用自身的模型能力,经过它回传给生成器的梯度也会跟着变差。
- weight clipping会导致很容易一不小心就梯度消失或者梯度爆炸。原因是判别器是一个多层网络,如果我们把clipping threshold设得稍微小了一点,每经过一层网络,梯度就变小一点点,多层之后就会指数衰减;反之,如果设得稍微大了一点,每经过一层网络,梯度变大一点点,多层之后就会指数爆炸。
因此产生了另一种实现李普希兹连续的方法:gradient penalty ,它应用在Improved WGAN(WGAN-GP) 中,可以很好地解决上面两个问题。
事实上,要求判别器满足 Lipschitz 连续其实就是要求它的梯度的范数对所有的输入都不超过 K, 因此我们可以直接显式地在损失函数中加入一个惩罚项,例如:
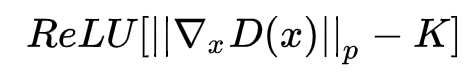
或者
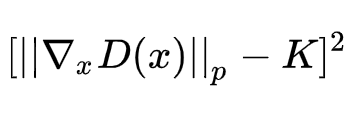
尽管理论上前者就行了,但是论文作者选的是后者,因为实验上表现更好。接着我们简单地把K定为1,再跟WGAN原来的判别器loss加权合并,就得到新的判别器loss:

可是第三个分布要求我们在整个样本空间 \(\mathcal X\) 上采样,这实际上没法做到。
因此我们进行一个近似:假设 x 是从一个事先定好的分布 \(P_{penalty}\) 中采样出的。我们只需要去确保在这个分布的范围内判别器梯度的范数会小于 1. 至于这个分布,我们假设只考虑生成分布和真实分布之间夹着的中间区域,我们在这里进行采样。
具体来说,就是我们先随机采样一对真假样本,以及一个 0-1 的随机数,然后在它们的连线上随机插值取样,便得到了一个采样。
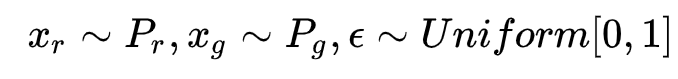
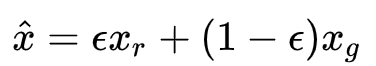
最终的 Loss 为:
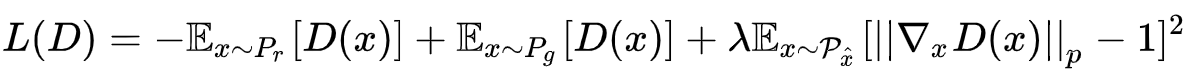
由于我们是对每个样本独立地施加梯度惩罚,所以判别器的模型架构中不能使用Batch Normalization,因为它会引入同个batch中不同样本的相互依赖关系。
然而 Improved WGAN 所采用的方法也有许多问题,例如直接连线的随机插值取样可能导致分布并不是处于中间的分布等等。
- Spectrum Norm(谱归一化)
谱归一化对 WGAN 进行了新的扩展,它从理论上保证了判别器的梯度始终可以小于 1,而非只是作出惩罚。 基本思想就是让网络每一层的权重矩阵 \(W\) 的所有元素每次都除以它的最大的特征值,而这一最大特征值使用了近似算法 power iteration 来求解。
- Loss-sensitve GAN
这个 LSGAN 与 WGAN 的理论很相似,在实践中,它具体就是对判别器认为较为真实的生成样本设置一个 threshold ,让它同真实样本的 margin 相比于更假的样本要小一点。

八、生成样本的评估
衡量生成样本的质量同样也很重要,现在普遍的评估标准就是拿一个事先训练好的分类网络(如 Inception)对生成样本进行分类,输出一个分布 P(y|x) ,如果这个分布比较集中,就表明生成样本足够清晰。

同时为了避免 mode collapse 的问题,我们还需要用多组样本喂入分类器,然后得到一个平均分布,如果这个分布表现得很平均,表明了没有 mode collapse 问题。

一个 score 叫做 Inception Score, 因为它采用 Inception 网络。

对于它的拓展称作 Fréchet Inception Distance(FID),这也是现在最常使用的评价指标。
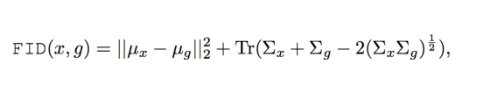
其中 x 代表真实样本,g 代表生成样本,
一般情况下IS评价指标的使用很少,因为它只考虑了GAN生成样本的质量,并没有考虑真实数据的影响。IS用Inception V3直接输出类别,而FID则用其输出特征。FID距离计算真实样本,生成样本在特征空间之间的Wasserstein-2 distance或者Frechet distance距离。首先利用Inception网络来提取特征,然后使用高斯模型对特征空间进行建模,再去求解两个特征之间的距离,较低的FID意味着较高图片的质量和多样性。
另外,我们怎样才能知道我们的生成样本不是单纯记忆数据集里面的样本而是新的样本呢(过拟合)?我们不能直接检测生成样本和数据集里面图片的差异,因为将图片平移几个像素都有可能与原图差异大大增加。 这个问题有一些方法衡量,但是还有待开发。
接下来介绍一些目前比较流行的模型
九、更大,更好—— StyleGAN
我们怎样才能让 GAN 生成高质量的大图像(1024 x 1024)呢? 一个比较自然的想法就是先使用非常低分辨率的图像(如:4x4) 开始训练,然后逐步扩大网络,最后便产生一个拥有丰富细节的高清图片。这便是 ProGAN (StyleGAN前身)的想法。

这项技术首先通过学习在低分辨率可以显示的基本特征,然后随着分辨率的提高,学习越来越多的细节,低分辨率图像的训练简单快速且有助于高级别的训练,因此整体的训练更快。
注意网络结构并不是 4x4 连接到 8x8 再到 16x16 的,而是动态变化,生成器内部的网络只有一个。这种突变导致了网络的参数会失效,因此 ProGAN 采用了一种平滑过渡的技术:

如图,当把生成器和判别器的分辨率加倍时,会平滑地增大新的层。在转换过程(b)中,输出的样本 \(X=X_{low}*(1-\alpha)+X_{high}*\alpha\) 我们把权重 α 从 0 到 1 线性增长,使得样本进行平滑过渡。图中的 2x 和 0.5x 表示利用最近邻卷积和平均池化对分辨率放大和缩小,另外,toRGB 和 fromRGB 是两个映射层,它们采用 1x1 卷积,实现了由更多的通道转向 RGB 通道的映射与还原。 当训练判别器时,插入下采样后的真实图片去匹配网络中的当前分辨率。在分辨率转换过程中,会在真实图片的不同分辨率之间插值,类似于将两个分辨率结合到一起用生成器输出。
然而 ProGAN 并不能控制它所生成图片的特定特征,一个输入可能会影响多个特性,因此我们希望有一种更好的模型,能让我们控制住图片的样子,并且每个输入维度之间的影响尽可能小。于是便有了 StyleGAN:
StyleGAN 发现渐进层的一个潜在的好处就是:如果使用得当,就能够控制图像的不同视觉特征。层和分辨率越低,它影响的特征就越粗糙:
- 粗糙的——分辨率小于 8x8,影响姿势,一般发型,脸型等等;
- 中等的——分别率介于 162 ~ 322 之间,影响更精细的面部特征如眼睛的闭合等;
- 精细的——分辨率高于 64x64,此时影响许多微观特征如颜色等。
StyleGAN通过增添许多附加模块实现了样式上更细微和精确的控制:
1. 映射网络
StyleGAN 给生成器的输入加上了 8 个全连接层组成的映射网络,且输出与输入大小一样。

这个目的就是将输入向量进行编码生成控制向量,使得它的不同元素能够控制不同的视觉特征。控制向量的不同元素之间代表的特征不会纠缠在一起。
至于为什么 Mapping Network 可以学习到特征解耦呢?直观地想若仅使用输入向量控制视觉特征,能力是很有限的,因为它遵循着训练数据的概率密度,即判别器的评分会影响生成器的分布,此时输入的许多值都会对概率较大的特征产生影响。但是若使用另一个神经网络,使得可以生成一个不必遵循训练数据分布的向量,就可以减少特征之间的相关性。
最后得到的特征在每个分辨率的网络中会由一层神经元进行仿射变换,让神经网络最后选择这个分辨率所需要的特征,然后最后得到输出 \(\bold{y=(y_s, y_b)}\),用于下一步的实例归一化。
2. AdaIN(Adaptive Instance Normalization)
AdaIN,自适应实例归一化。AdaIN层扮演了一个类似的风格交换层的角色,它把选择的特征(style)加入到输入中,

如图,具体来说,在得到特征向量 W 后,经过仿射变换层 A 进行选择特征,最后得到(2xn)大小的矩阵,每一列对应一个卷积核产生的特征图,最后代入公式计算即可。这个过程在每次上采样和卷积后都进行一次。
3. 删除传统输入
传统 GAN 的输入就是一个随机向量,但是 StyleGAN 的特征向量是在过程中插入的,因此它的初始输入就可以被忽略,并使用一个常量值替代。这样子不仅可以降低生成不正常照片的概率,还可以减少特征纠缠。

4. 随机变化

加入的噪声可以产生人脸上的许多小的特征,例如雀斑、发际线、皱纹等等,这里的噪声是逐通道进行生成加入。噪声可以使生成的图像更加的真实多样。
此外,StyleGAN 还使用了截断中间向量 W 的技巧,就是选择多个随机输入,生成中间向量后计算它们的均值,在生成新的图片时,使用 \(W'_{new}=W'_{avg}+ \Psi(W'-W'_{avg})\) , 其中的参数定义了图像与平均图像的差异量,如图:

5. Style Mixing
StyleGAN 还有一个有趣的地方就是它可以进行样式混合,即把一个图片的特征融合进入另一个图片当中。

如图,第一列是不进行融合生成的图像,最上面一行是其他的生成图像。如果把最上面的图像的特征向量分别代替原向量喂入粗糙的(2-3行)、中等的(4-5行)、精细的(6行)对应的AdaIN中就会产生神奇的效果,这进一步说明了 StyleGAN 能够控制特征的强大功能。这种融合也可以提高模型的泛化性。
StyleGAN的总体结构大致如下:

另外,StyleGAN 没有使用 spectrum norm,WGAN-GP loss,等等技巧,且它的网络架构是简单的前馈网络,因此它还有很大的改进空间,还有它最明显的缺陷是生成的图像有时包含斑点似的伪影(artifacts)
因此便产生了 StyleGAN2,它的主要改进包括:
- 生成的图像质量明显更好(FID分数更高、artifacts减少)
- 提出替代progressive growing的新方法,牙齿、眼睛等细节更完美
- 改善了Style-mixing
- 更平滑的插值(额外的正则化)
- 训练速度更快
如图,右边两列是改进的方法,使用了 “demodulation” 代替 AdaIN 可以去除伪隐影。 另外 StyleGAN2 还改进了前馈网络,测试了 skip connection 、残差网络以及分层方法.

十、图像翻译——GauGAN(SPADE)
GauGAN 研究的是在给定一张语义分割图时合成对应的实际图像,英文名为semantic image synthesis。 如图(上面是语义,左边是风格):

在之前,pix2pixHD 是这个方面的经典算法,GauGAN 发现 pix2pixHD 这样的算法都是将语义分割图直接作为输入进行计算,但是一旦这些生成网络使用传统的归一化层(BN),就容易丢失输入语义图像中的信息,如图:

因此提出了新的归一化层:Spatially-Adaptive Normalization(SPADE) 来解决这一问题。
SPADE 在 BN 的基础上进行了修改,公式如图:

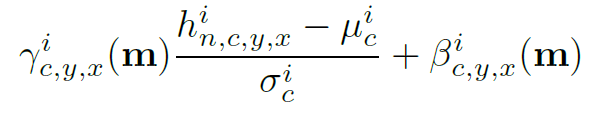
在传统 BN 中,γ 和 β 都是一维向量,每个值对应着轴通道,而在 SPADE 中,它们是三维矩阵,除了通道维度,还有高和宽的维度,因此有了公式中的下标,这也是 spatially adaptive 的含义。
我们不难发现这个好像与 StyleGAN 中的 AdaIN 的实现方式差不多,事实上只要几个小的改动就可以变成 AdaIN,但是对于语义图像,SPADE 的表现更适合。使用 SPADE 可以更好的防止语义信息被标准化消失掉,同时又具有标准化的优点。
最后由于语义图像是在 SPADE 过程中输入进网络的,我们的输入可以变成一个样式图像,从而可以生成指定的 style。SPADE 的生成器使用了含 SPADE 的残差网络,如图:

十一、单样本学习—— SinGAN
SinGAN 是一个可以从单张自然图像学习的非条件性生成式模型,它可以捕捉给定图像中各个小块内在的分布,然后产生和图像视觉内容相同且多样的新图像。 SinGAN 的结构是多个全卷积GANs组成的金字塔,它们负责学习图像中的某个小块的数据分布。这种设计可以让它生成具有任意大小和比例的新图像,这些新图像在具有给定的训练图像的全局结构和细节纹理的同时,还可以有很高的可变性。SinGAN 是一个非条件模型,即输入是随机噪声。
此外,SInGAN可以通过同样的架构去实现多种任务,例如单个图像到图像的绘制、编辑、协调、超分辨率和动画。 效果如图:

多任务,注意这里网络只观察过第一行的训练数据且没有额外的架构修改或是调参:

SinGAN 的总体架构:

同样运用了 ProGAN 的思想,可见这是 GAN 的一种趋势。但是 SinGAN 的不同 scale 之间是分开训练的,前一个训练完它的参数就固定了,将生成的图像传递给下一个 scale。
对于单个的 scale , 它使用了残差结构:

SinGAN 证明了 GAN 可以学习单一图像的完全分布,从噪声完全生成具有逼真细节、清晰纹理的自然图像。
个人尝试了一下 SinGAN 进行动画生成,发现效果还不错——

这张是从第二层进行生成的,如果从更低的层生成,对于我这个训练图像,它的生成就很不真实:

不难理解这是因为较低层的轻微改变被上采样不断扩大从而导致生成的样本不自然。
但是如果对于一些其他图像,是完全可以从底层开始生成的:
[video(video-H9uTQTtW-1582608485913)(type-bilibili)(url-https://player.bilibili.com/player.html?aid=74714613)(image-https://ss.csdn.net/p?http://i0.hdslb.com/bfs/archive/db9574ed609166b5ee8ef1a99c07cbb87fe54028.jpg)(title-SinGAN for single image animation)]
十二、GAN 的下一步
学习了这么多 GAN 的结构和思想,不由得会产生一些直觉,让我们想象 GAN 的下一步会是什么。谷歌大脑的研究员Augustus Odena在distill上发表了一篇新的文章,就提出了关于GAN的七个问题,这些问题都是 GAN 发展的方向。

1. GAN 是否会被取代
除了GAN以外,目前还有另外两种比较流行的生成模型:流模型(Flow Models)和自回归模型(Autoregressive Models)。最近的研究成果表明,这些模型具有不同的性能特征和权衡。GAN并行高效但不可逆;流模型允许精确的对数似然计算和精确推理,但效率低;自回归模型可逆且高效,但不并行。

那么 GAN 和其它生成模型之间的基本权衡是什么呢? 这就需要我们去研究更多的模型,同时尝试进行混合模型,说不定会有更好的表现,各取其长。
2. GAN 给指定分布建模有多难
大多数GAN研究侧重于图像合成,人们往往都是用MINIST、CIFAR-10、STL-10、CelebA和Imagenet这样的数据集来训练GAN。而哪些数据集更容易建模,总有一些坊间传闻,但如果想要验证这些结论,那就复杂了。
Augustus Odena指出,与任何科学一样,GAN也希望有一个简单的理论来解释实验结果。
于是问题二就来了:我们怎么才能知道用GAN建模有多难?
大牛建议从两个方面着手:
合成数据集——通过研究合成数据集来探究哪些特征会影响学习性
修改现有的理论结果——尝试修改现有理论结果的假设来解释数据集的不同属性
3. GAN只能合成图像吗
GAN在图像合成领域的成绩有目共睹,而在图像合成之外,Augustus
Odena提到了三个主要受到关注的领域:文本,结构化数据,音频。
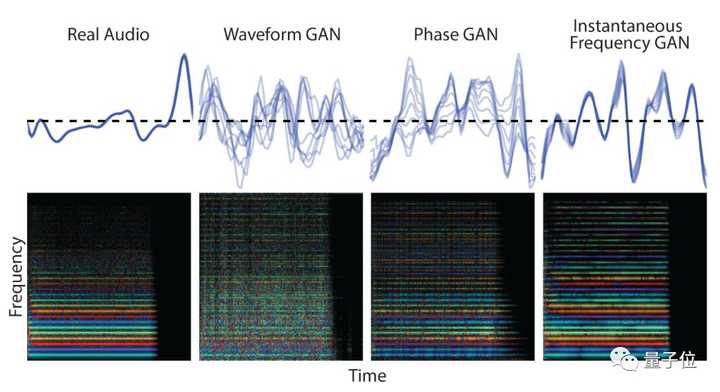 (快速生成高保真音频的新方法GANsynth, Jesse Engel, 2019)
(快速生成高保真音频的新方法GANsynth, Jesse Engel, 2019)
在无监督音频合成方面GAN是比较成功的,但在其他方面还是乏善可陈。 那么如何才能使GAN在非图像数据上表现得更好呢?这就是第三个问题。
对于连续型的数据,我们可能需要找到更好的隐含先验信息,并且这些信息是可以在给定的域里能计算出来的。
而对于结构性数据或是离散数据,我们并不确定什么可以改进,但是也许可以让判别器和生成器进行强化学习。或者这类问题只是缺少一些更基础性的研究进展。
4. GAN 的收敛问题
GAN 的训练过程是在同时优化发生器和鉴别器,让两个 AI 相互对抗,而这很可能导致模型不收敛。
目前有三种路线都有所突破但尚未完成:
- 简化假设——简化关于生成器和判别器的假设。例如简化的 LGQ GAN,通过特殊技术优化,它可以证明先行生成器,高斯数据以及二次鉴别器是全局收敛的。
- 使用普通神经网络的技术——应用分析普通神经网络(非凸)的技术来回答 GAN 的收敛性问题。在前面的文章中介绍了深度学习其实并不一定需要全局收敛,但这种分析能否提升到 GAN 上呢?
- 博弈论——可以使用博弈论中的概念为 GAN 训练建模。这种技术产生的训练过程可以证明是收敛到近似的纳什均衡,但是这会导致不合理的资源约束。因此下一步就是减少这些约束。
5. GAN 的评估问题
前面我们也说过,关于 GAN 的评估标准有很多但没有共识。例如有:
- FID——只能衡量样本质量而不能衡量样本多样性。
- MS-SSIM——评估多样性,但是存在一些问题。
- AIS——建议在GAN的输出上使用高斯观测模型,并使用退火的重要性采样来估计在此模型下的对数可能性。
- ……
关于如何评估 GAN 的困惑实际上源于对何时使用 GAN 的疑惑。 可能最终还是需要人的参与才可以真正衡量 GAN (生成模型的图灵测试?)
6. GAN 的训练如何按批的大小进行扩展
大部分GAN中的鉴别器只是一个图像分类器,如果瓶颈在于梯度噪声,那么增加批大小就能加速训练。但是GAN有一个不同于分类器的瓶颈:它的训练过程是不稳定的。
Augustus Odena于是提出了第六个问题:GAN训练如何按批大小进行扩展?梯度噪声在GAN的训练过程中扮演什么样的角色?是否可以修改GAN训练,使其随批处理大小更好地实现扩展?
他指出了三个解决方案,其中,他认为在批大小非常大的时候,Optimal Transport GANs会是不错的选择。而异步SGD也是一个值得关注的方法。
7. 判别器的对抗鲁棒性会怎样影响 GAN 的训练。
众所周知,图像分类器会受到对抗样本的影响:对抗样本与真实样本的区别几乎无法用肉眼分辨,但是却会导致模型进行错误的判断。由于GAN的鉴别器就是图像分类器,所以它也可能遭遇对抗样本的问题。
Augustus Odena提到,尽管有大量关于GAN和对抗样本的文献,但它们之间的关系却没有得到多少研究。
那么问题就来了:GAN和对抗样本之间有什么样的关系?鉴别器的对抗鲁棒性会如何影响GAN的训练结果?
Augustus Odena认为这个研究课题很有价值。对生成模型的蓄意攻击已经被证明是可行的,而遭到“意外攻击”的可能性虽然比较小,但也没有决定性的证据证明发生器不会产生对抗样本。
| 以上就是关于 GAN 的综述,我们学习了 GAN 的背后的数学思想,然后知道了 GAN 的 loss 的选择。学习了条件 GAN, 无监督 GAN 的经典结构与思想,认识了全新的 GAN 的算法结构,并有了对于 GAN 的下一步的初步认识。GAN 的论文每年都在激增,当然不可能学习全部的结构和算法,但是我们可以由一些经典架构学习到 GAN 背后巧妙的思想,并将这种思想或是直觉用于新的结构设计或是应用中。 |
| 本文参考了大量博客与教程论文,想要了解更多还请前往参考文章去继续深入。 |
参考文献及推荐阅读
- 前四节:
李宏毅的 GAN 课程:
油管:https://www.youtube.com/watch?v=DQNNMiAP5lw&list=PLJV_el3uVTsMq6JEFPW35BCiOQTsoqwNw&index=1
b站:https://www.bilibili.com/video/av24011528?from=search&seid=973385161043902032
课程主页(包含课程的课件和作业):http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLDS18.html
- WGAN 部分:
令人拍案叫绝的Wasserstein GAN https://zhuanlan.zhihu.com/p/25071913
- WGAN++ 部分:
知乎提问中 LSGAN 的作者郑华滨老师的回答https://www.zhihu.com/question/52602529/answer/158727900
进一步了解谱归一化: https://www.sohu.com/a/294399864_500659
另外郑华滨老师还将 WGAN 同 LSGAN 进行了比较和拓展
条条大路通罗马LS-GAN:把GAN建立在Lipschitz密度上:https://zhuanlan.zhihu.com/p/25204020
另外描述了WGAN与LSGAN共同属于的一个广义模型族GLSGAN: 广义LS-GAN(GLS-GAN): https://zhuanlan.zhihu.com/p/25580027
- 评估 GAN 部分:
FID 的教程How to Implement the Frechet Inception Distance (FID) for Evaluating GANs :https://machinelearningmastery.com/how-to-implement-the-frechet-inception-distance-fid-from-scratch/
从泛化性到Mode Collapse:关于GAN的一些思考(作者同样是郑华滨老师):https://zhuanlan.zhihu.com/p/36410443
- StyleGAN 部分:
论文: StyleGAN:https://arxiv.org/abs/1812.04948 StyleGAN2:https://arxiv.org/pdf/1912.04958.pdf
代码:https://github.com/NVlabs/stylegan https://github.com/NVlabs/stylegan2
StyleGAN的代码结构非常好,还是值得研究一下的,尤其是生成器的部分。 StyleGAN 从代码完全解读:https://blog.csdn.net/weixin_43013761/article/details/100895333 一个 StyleGAN的应用与研究网站,可以生成照片,并且还有许多 GAN 的研究笔记,很值得去看:http://www.seeprettyface.com StyleGAN 2 解读:https://zhuanlan.zhihu.com/p/97197133
这里有一个 GauGAN 的 demohttps://nvlabs.github.io/SPADE/demo.html


可以看到效果还不错。
代码:https://github.com/NVlabs/SPADE
GauGAN 的详细笔记:https://blog.csdn.net/u014380165/article/details/100110065
SinGAN 部分: 论文: SinGAN: Learning a Generative Model from a Single Natural Image 论文翻译: http://www.dataguru.cn/article-15165-1.html 代码:https://github.com/tamarott/SinGAN SinGAN 论文解读:https://zhuanlan.zhihu.com/p/92218525
GAN的下一步 部分:
distill上的文章: Open Questions about Generative Adversarial Networks https://distill.pub/2019/gan-open-problems/
以及知乎提问中 量子位的回答 :https://www.zhihu.com/question/52602529/answer/158727900
关于流(FLOW)模型的学习:https://blog.csdn.net/a312863063/article/details/94306107
人生苦短,不服就 GAN.
以上内容如有谬误还请告知指正。